I was listening to a podcast the other day about AI and the mathematics behind it — especially stochastic processes, entropy, and probability — and it immediately drew me in. With a background in electrical engineering and telecommunications, I have always found this intersection fascinating, so I decided to write this article. I hope you enjoy it.
There is a thread running through thermodynamics, information theory, and modern artificial intelligence — and it is deeper than analogy. The mathematics used to describe the disorder of a gas, the uncertainty of a message, and the optimization of a neural network are closely related. Understanding that connection is not merely academic. It clarifies why stochasticity and entropy are not bugs in AI systems, but foundational design principles.
This post traces that thread: from Boltzmann and Shannon to cross-entropy loss, temperature settings, and elliptic curves in modern cryptography. Physics, information theory, and language models rest on deeply connected mathematical foundations.
1. Stochastic: Governed by Probability
The word stochastic comes from the Ancient Greek στοχαστικός (stokhastikós), related to στοχάζομαι (“to aim, to guess”) and τόχος (“target”). In modern science and engineering, it means governed by probability. A stochastic process is one where outcomes are not deterministic; they are drawn from a probability distribution. Given the same initial conditions, you may get a different result each time.
The opposite is deterministic — the same input always yields exactly the same output. But not all randomness is the same.
Epistemic vs. Ontic Randomness
A coin flip, at the level of classical mechanics, is deterministic. Given exact knowledge of initial position, velocity, air currents, and surface properties, Newtonian physics would predict the outcome with certainty. The randomness we assign to it is epistemic — a product of our ignorance of initial conditions, not of any fundamental indeterminacy in nature. We model it as a fair Bernoulli trial because we cannot practically measure or control those conditions.
Thermal noise — Johnson–Nyquist noise — is different. It arises from the random thermal agitation of charge carriers in a conductor and is rooted in quantum and statistical mechanics. At practical engineering scales, such fluctuations are treated as fundamentally irreducible and modeled statistically. This is ontic randomness — intrinsic to the physical system.
Epistemic randomness reflects our ignorance; in principle, a perfect observer could remove it. Ontic randomness is intrinsic; no amount of additional information eliminates it. This distinction matters for how we interpret probabilistic models in physics, engineering, and AI.
2. Entropy in Communications: Shannon’s Measure of Uncertainty
In 1948, Claude Shannon published A Mathematical Theory of Communication. He defined a precise mathematical measure of uncertainty — which he called entropy — deliberately borrowing the term from thermodynamics.
Shannon entropy measures the average uncertainty of an information source:
H(X) = −∑ p(x) · log₂ p(x)
Where p(x) is the probability of each possible symbol. If a source always sends the same symbol, entropy is zero — no surprise, no information. If all symbols are equally likely, entropy is maximized — maximum uncertainty and maximum information per symbol.
Shannon entropy is the theoretical lower bound on how many bits you need to encode a message without loss. It answers the question: how unpredictable is this source? A source with low entropy can be heavily compressed. A source with high entropy cannot be compressed further — it is already maximally dense with information.
This is the foundation of data compression and channel capacity theory. The famous Shannon limit defines the maximum rate at which information can be transmitted over a noisy channel without error.
3. Thermodynamic and Information Entropy: Shared Mathematical Form
The relationship between Shannon’s information entropy and Boltzmann’s thermodynamic entropy is not a metaphor. It is a deep mathematical connection.
Boltzmann defined thermodynamic entropy as:
S = k · ln(W)
Where k is Boltzmann’s constant and W is the number of possible microstates a physical system can occupy. A gas with molecules spread randomly everywhere has more possible configurations — higher entropy. A perfectly ordered crystal has very few microstates — low entropy.
When Shannon showed his formula to John von Neumann and asked what to call it, von Neumann reportedly replied: “Call it entropy. Nobody knows what entropy really is, so in a debate you will always have the advantage.”
Beyond the wit, Shannon recognized something profound: the formulas are closely related in structure. Both describe multiplicity, uncertainty, and the distribution of possible states. Both measure, in different domains, how much is not fully specified about a system.
Landauer’s Principle: Information Has Physical Cost
Maxwell’s Demon — a thought experiment from 1867 — imagined a tiny demon sorting fast molecules from slow ones, seemingly reducing thermodynamic entropy without doing work. The resolution, formalized by Rolf Landauer, is that the demon must store information about each molecule. When it erases that information from memory, that erasure costs energy and generates heat.
Landauer’s Principle: Erasing one bit of information dissipates a minimum amount of energy and produces a corresponding increase in thermodynamic entropy.
Information is not abstract. It has a physical cost. The second law of thermodynamics and the limits of data compression are deeply connected constraints viewed from different angles.
| Thermodynamics | Information Theory |
|---|---|
| Physical disorder | Message unpredictability |
| Heat dissipation | Bit erasure cost |
| Second law: entropy increases | Cannot compress below Shannon entropy |
| Equilibrium tends toward high entropy | Random noise is a maximum-entropy source |
4. How These Concepts Percolate into AI
Stochastic processes and entropy are structurally embedded in how neural networks are trained, how language models generate text, and how reinforcement learning agents explore.
Cross-Entropy Loss
The most widely used training objective in neural networks — especially for classification and language models — is cross-entropy loss. It measures how different the model’s predicted probability distribution is from the target distribution. Minimizing cross-entropy loss is equivalent to maximizing the likelihood of correct outputs. Every time a language model trains, it is performing optimization grounded in Shannon-style information measures.
Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) samples random mini-batches instead of computing gradients over the full dataset. The randomness this introduces is not merely a computational shortcut — it also helps models explore the loss surface more effectively than a fully deterministic optimizer would.
Temperature as an Entropy Control
When a large language model generates the next token, it samples from a probability distribution over the vocabulary. Temperature directly affects the entropy of that distribution:
- Low temperature — peaky distribution, near-deterministic, low entropy. The model tends to pick the highest-probability token.
- High temperature — flatter distribution, more random, higher entropy. The model explores less likely but sometimes more creative options.
When you adjust temperature in an LLM, you are rescaling the logits, which usually makes the next‑token distribution lower‑entropy (more peaked) at low temperatures and higher‑entropy (flatter) at high temperatures. In doing so, you reshape uncertainty in the output distribution. Physics, information theory, and language models all rely on closely related mathematics.
KL Divergence and Entropy Regularization
Kullback–Leibler divergence measures how one probability distribution diverges from another. It is defined in terms of entropy and is used in settings such as variational autoencoders and RLHF to keep models from drifting too far from a target distribution.
In reinforcement learning, entropy regularization — used in algorithms like Soft Actor-Critic (SAC) — explicitly rewards a policy for maintaining high entropy, encouraging exploration rather than premature collapse into a single deterministic strategy.
5. Appendix: Elliptic Curve Cryptography — Related Mathematical Thinking
These ideas also surface in modern cryptography, where secure systems rely on mathematical structure, one-way functions, and carefully managed randomness.
An elliptic curve is defined by the Weierstrass equation:
y² = x³ + ax + b
In practical cryptography, elliptic curves are defined over finite fields, turning the curve into a discrete set of points with useful algebraic properties.
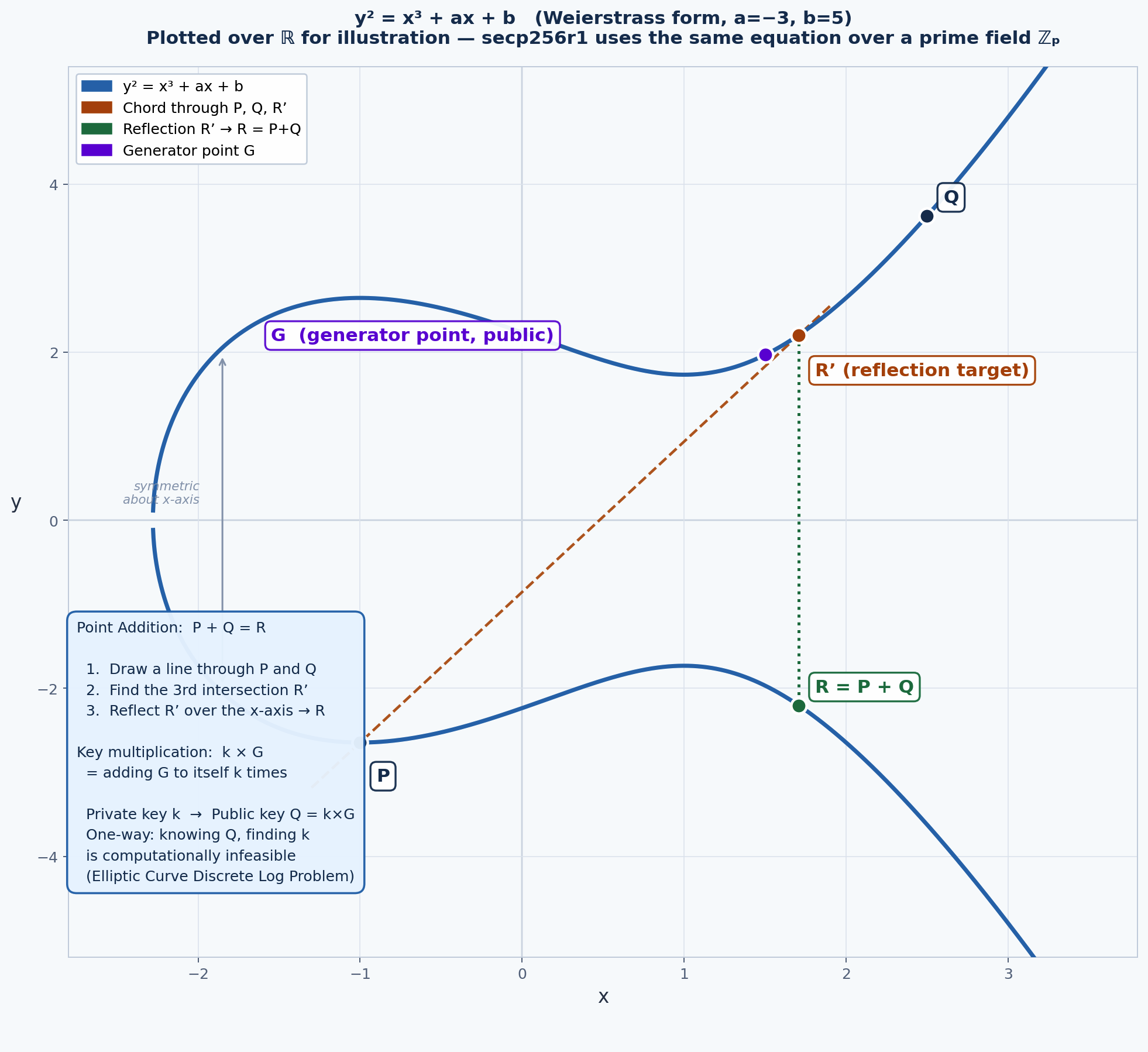
Public key Q = Private key k × G
Where G is a fixed public generator point and k is a secret private integer. Point multiplication means repeated elliptic-curve addition under well-defined algebraic rules.
Why this is a one-way function: Computing Q from k is efficient. Recovering k from Q and G is computationally infeasible. This is the Elliptic Curve Discrete Logarithm Problem (ECDLP). A 256-bit elliptic-curve key is commonly regarded as offering security comparable to a 3072-bit RSA key.
The connection to entropy is subtle but important: digital signature schemes such as ECDSA rely on per-signature randomness. If that randomness is reused or becomes predictable, the private key may be exposed. In cryptography, randomness is not a convenience. It is a security requirement.
Key Takeaways
Stochasticity is the mechanism — uncertainty is not a failure of understanding, but a fundamental feature of physical and informational systems.
Entropy is the measurement — a precise mathematical way to quantify that uncertainty.
These domains share related mathematical structures — from Boltzmann in the nineteenth century to Shannon in the twentieth, and from there to cross-entropy loss, temperature scaling, and KL divergence in modern AI.
Information has physical cost — Landauer’s principle links information theory and thermodynamics at a physical level.
Cryptography and AI both depend on structured uncertainty — whether in probabilistic modeling, optimization, or secure randomness.
The second law of thermodynamics and the limits of data compression are deeply connected constraints, viewed through different lenses. The disorder of a physical system, the uncertainty of a message, and the probabilistic behavior of a language model can all be described using closely related mathematical ideas. That is one of the most elegant continuities in the history of science.
References
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379–423.
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183–191.
- Cover, T. M., & Thomas, J. A. (2006). Elements of Information Theory (2nd ed.). Wiley.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. (Chapters on cross-entropy, SGD, and variational methods.)
- Hopsworks (2025). LLM Temperature. Covers low-T = peaked/predictable and high-T = flat/creative in LLMs.
- Gebodh, N. (2024). Why Does My LLM Have A Temperature?. Softmax and temperature math.