We casually say “AI can write, AI can draw, AI can code” as if it’s one thing. It’s not. Two of the most talked-about model families in AI today solve fundamentally different problems using fundamentally different mechanisms — and conflating them leads to bad engineering decisions, bad product expectations, and bad policy.
This post breaks down the two architectures that dominate the current AI landscape: Transformers and Diffusion Models. What they do, how they work, and why the distinction matters.
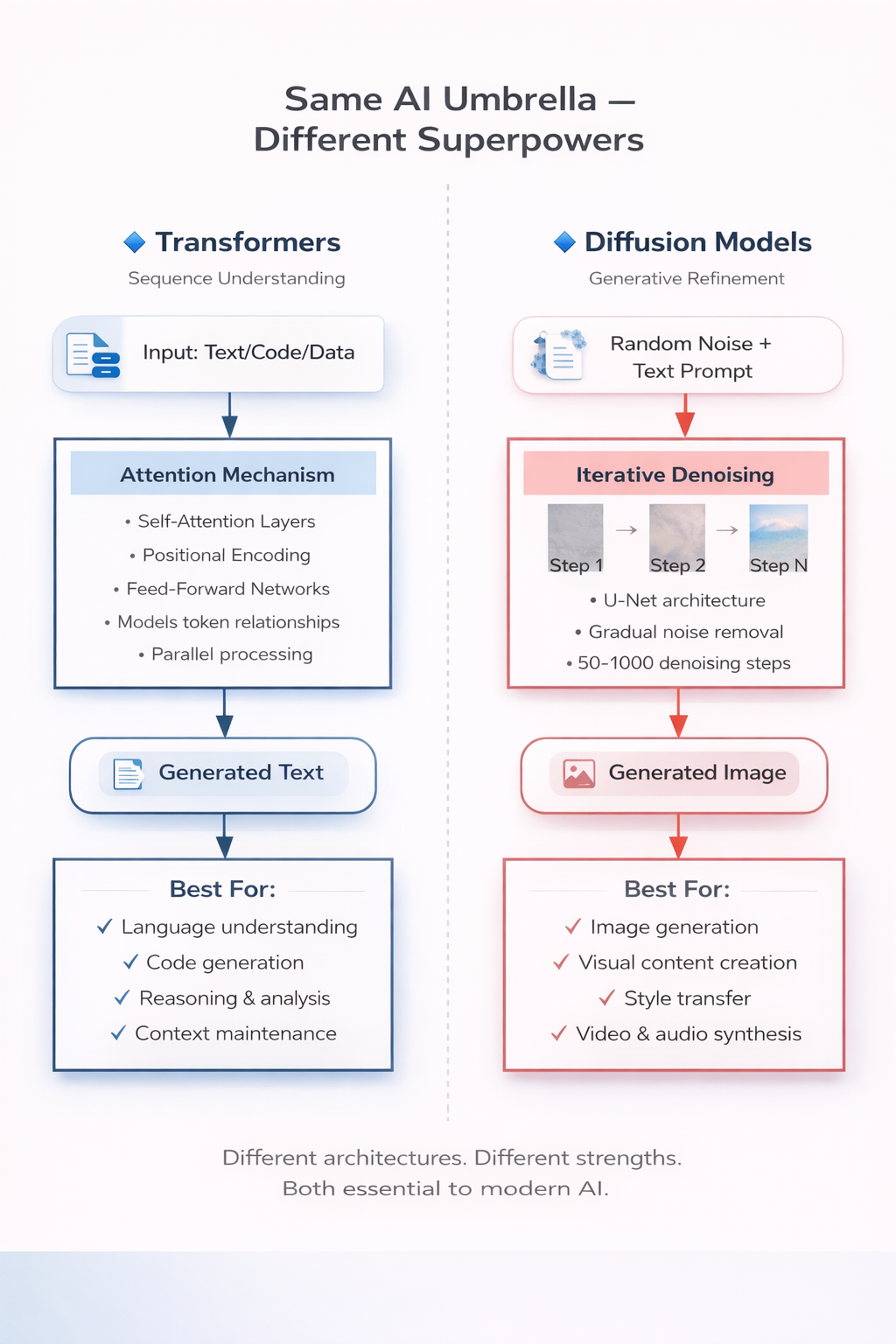
Transformers: Sequence Understanding Machines
The Transformer architecture was introduced in the 2017 paper “Attention Is All You Need” by Vaswani et al. at Google. It replaced recurrent neural networks (RNNs) as the dominant architecture for sequence modeling, and it’s now the foundation of virtually every major language model — GPT, Claude, Gemini, LLaMA, Mistral, and others.
What They Do
Transformers model relationships within sequences. Given a sequence of tokens (words, subwords, code tokens, or any structured data), the Transformer learns which tokens are relevant to which other tokens — regardless of their distance in the sequence. This is the core innovation: self-attention.
They excel at:
- Language understanding — parsing meaning, context, and nuance from text
- Text generation — producing coherent, contextually appropriate language
- Code generation and reasoning — understanding syntax, logic, and structure
- Sequence-to-sequence tasks — translation, summarization, question answering
How They Work
At a high level:
- Input tokenization: Text is split into tokens and converted to numerical embeddings
- Positional encoding: Since Transformers process all tokens in parallel (not sequentially like RNNs), position information is added explicitly
- Self-attention layers: Each token attends to every other token in the sequence, computing relevance scores. This is what allows the model to capture long-range dependencies — a word at the beginning of a paragraph can directly influence the interpretation of a word at the end
- Feed-forward layers: After attention, each token passes through a feed-forward network for further transformation
- Stacking: Multiple layers of attention + feed-forward are stacked (modern models use dozens to over a hundred layers), building increasingly abstract representations
- Output generation: For generative models, the output is a probability distribution over possible next tokens, sampled autoregressively — one token at a time
The Key Insight: Attention
The self-attention mechanism computes, for every token in the input, a weighted sum of all other tokens based on learned relevance. This allows the model to focus on the right context dynamically. When you ask a language model about “the bank” in a sentence about rivers, attention helps it distinguish that from “the bank” in a financial context — by looking at surrounding tokens.
This is computationally expensive (quadratic in sequence length), which is why context window sizes, efficient attention variants, and inference optimization are active areas of research.
Diffusion Models: Generation from Noise
Diffusion models took a different path. Instead of modeling sequences, they model the distribution of data — typically images — and generate new samples by reversing a noise process.
The key papers include “Denoising Diffusion Probabilistic Models” (Ho et al., 2020) and the latent diffusion work behind Stable Diffusion (Rombach et al., 2022). These models power most of today’s image generation tools: DALL-E, Midjourney, Stable Diffusion, and increasingly video and audio generation.
What They Do
Diffusion models generate high-quality, coherent data from random noise. They’re primarily used for:
- Image generation — photorealistic images, art, design assets
- Image editing — inpainting, outpainting, style transfer
- Video generation — emerging applications producing short video clips
- Audio synthesis — music and speech generation
How They Work
The process has two phases:
Forward process (training):
- Take a real image from the training set
- Gradually add Gaussian noise over many timesteps until the image becomes pure random noise
- The model learns to predict and reverse each step of this corruption
Reverse process (generation):
- Start with pure random noise
- The model iteratively removes noise, step by step
- Each step refines the image, adding structure and detail
- After enough steps, a coherent, realistic image emerges
The model doesn’t “understand” images in the way a human does. It has learned the statistical structure of image data — what pixel patterns, textures, shapes, and compositions are likely — and uses that knowledge to guide the denoising process.
What makes this powerful is how the prompt steers the process. At each denoising step, the model predicts a slightly cleaner version of the image, using the text prompt as a guide for what should emerge from the noise. Over many steps — typically 50 to 1000 — the noise fades and coherent structure appears: edges sharpen, textures form, composition resolves. The prompt doesn’t create the image directly; it shapes the direction the denoising takes at every step.
This capability is already transforming fields beyond engineering — design, marketing, media, accessibility. It allows AI systems to take an idea expressed in one form (language) and bring it to life in another (visual). That cross-modal translation is what makes diffusion models architecturally significant, not just technically impressive.
The Key Insight: Iterative Refinement
Unlike a Transformer that produces output in a single forward pass (or token-by-token), diffusion models produce output through many refinement steps. This iterative process is what gives them their characteristic quality — but also makes them slower than single-pass models.
Modern variants (latent diffusion) work in a compressed latent space rather than directly on pixels, dramatically reducing computational cost while maintaining quality.
Side-by-Side Comparison
| Aspect | Transformers | Diffusion Models |
|---|---|---|
| Primary domain | Language, code, structured sequences | Images, video, audio |
| Core mechanism | Self-attention over token sequences | Iterative denoising of noise |
| Output method | Autoregressive (token by token) | Iterative refinement (many steps) |
| Training data | Text corpora, code repositories | Image datasets, visual data |
| Strengths | Context understanding, reasoning, generation of structured output | High-quality visual generation, creative content |
| Limitations | Quadratic attention cost, hallucination, sycophancy | Slow generation, less control over fine details, prompt sensitivity |
| Key papers | Attention Is All You Need (Vaswani et al., 2017) | Denoising Diffusion Probabilistic Models (Ho et al., 2020) |
| Example systems | GPT-4, Claude, Gemini, LLaMA | DALL-E, Midjourney, Stable Diffusion |
Where They Converge
The line between these architectures is blurring. Modern multimodal systems increasingly combine both:
- Vision Transformers (ViT) apply Transformer attention to image patches, bringing sequence-modeling techniques to visual understanding
- Diffusion Transformers (DiT) replace the traditional U-Net backbone in diffusion models with Transformer blocks, improving scalability and quality
- Multimodal models like GPT-4o and Gemini process both text and images, using Transformer-based architectures that understand across modalities
The trend is clear: future AI systems won’t be purely one or the other. They’ll be hybrid architectures combining the sequence understanding of Transformers with the generative capabilities of diffusion — and potentially other approaches entirely.
Why This Matters for Engineers
If you’re building products or systems that use AI, understanding these distinctions is not academic — it’s practical:
Choosing the right tool. A Transformer-based model won’t generate photorealistic images well. A diffusion model won’t reason about your codebase. Knowing which architecture fits your problem saves time and avoids building on the wrong foundation.
Setting realistic expectations. Transformers hallucinate. Diffusion models can produce artifacts. Both have failure modes that are architectural, not just tuning issues. Understanding the architecture helps you anticipate and mitigate failure.
Evaluating vendor claims. When someone says “our AI can do everything,” understanding that there’s no single architecture that excels at everything helps you ask better questions and make better decisions.
Designing for the future. Hybrid and multimodal architectures are where the industry is heading. Understanding the building blocks — attention, diffusion, latent spaces, autoregressive generation — positions you to evaluate and adopt new systems as they emerge.
The Bigger Picture
We’re in a moment where “AI” has become a single word that covers dozens of fundamentally different systems. Lumping them together is convenient for marketing but dangerous for engineering.
The future won’t be one model to rule them all. It will be specialized architectures with different strengths, working together — Transformers handling language and reasoning, diffusion models handling visual generation, and new architectures we haven’t seen yet handling problems neither can solve alone.
Understanding what’s under the hood isn’t optional. It’s what separates engineers who use AI effectively from those who just use it.
References
- Vaswani, A. et al. “Attention Is All You Need.” NeurIPS 2017. arxiv.org/abs/1706.03762
- Ho, J. et al. “Denoising Diffusion Probabilistic Models.” NeurIPS 2020. arxiv.org/abs/2006.11239
- Rombach, R. et al. “High-Resolution Image Synthesis with Latent Diffusion Models.” CVPR 2022. arxiv.org/abs/2112.10752
- Dosovitskiy, A. et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ICLR 2021. arxiv.org/abs/2010.11929
- Peebles, W. & Xie, S. “Scalable Diffusion Models with Transformers (DiT).” ICCV 2023. arxiv.org/abs/2212.09748
- The Obsolescence Paradox: Why the Best Engineers Will Thrive in the AI Era — understanding AI architectures as an engineering discipline